Superhelden der Digitalisierung: Data Scientists und die fünf Fragezeichen


Foto: pixabay/alan9187
Data Scientists sind die neuen Superhelden der Digitalisierung. Jede Firma will sie im Team haben, weil sie eine unglaubliche Fähigkeit besitzen: aus einem Berg von Daten die entscheidenden Informationen herauszupressen. Wie mit Röntgenaugen erkennen sie unsichtbare Muster, wo andere nur weißes Rauschen sehen. Und zwar in Sekundenschnelle. Deshalb erstaunt es, dass so ein Data Scientist eigentlich immer nur dieselben Fragen beantwortet, wie unsere Kollegen im Think-Big-Blog berichten.
Für ihre Arbeit benötigen Data Scientists zwei Elemente: Daten und Algorithmen. Das gilt auch für Laura Velikonja, die gerade ihre Tätigkeit bei Telefónica Deutschland in einem Interview vorstellte. Auch bei ihren Analysen dreht sich alles um diese fünf Fragen:
- Ist das A oder B?
- Ist das normal oder passiert gerade etwas Ungewöhnliches?
- Wie viel wird das?
- Wie ist es organisiert?
- Und was sollen wir jetzt tun?
Um sie zu beantworten, kochen Data Scientists ein spezielles Süppchen: Die Daten sind ihre Zutaten und Algorithmen sind die Rezepte, die ihnen sagen, wie man sie aufbereiten und kombinieren soll. Zu jeder Frage gehört eine bestimmte Sorte von Algorithmen, die wir uns heute einmal ansehen.
Frage 1: Ist das A oder B?
A oder B? Ja oder Nein? Äpfel oder Birnen? Zur Beantwortung solcher Fragen nutzen Data Scientists ihre Klassifikationsalgorithmen.
Sie können aus zwei Klassen bestehen, wenn es nur zwei mögliche Antworten gibt (A oder B?), oder aus vielen, wenn noch mehr Antworten möglich sind. Damit lassen sich solche Fragen beantworten:
- Wird dieses Bauteil in den kommenden Tagen kaputt gehen?
- Was bringt mehr Kunden: ein Gratis-Gutschein oder ein Rabatt?
- Ist das ein positiver Tweet?
- Welchen Service wird der Kunde auswählen: A, B oder C?
Der Algorithmus ordnet also die neuen Daten seinen vorhandenen Kategorien zu. Ein Beispiel dafür sind die sogenannten Entscheidungsbäume.
Frage 2: Ist das normal oder ungewöhnlich?
Mit dieser Frage untersucht ein Data Scientist, ob der Strom seiner Daten normal verläuft oder nicht. Um sie zu beantworten, nutzt er Algorithmen zur Erkennung von Anomalien. Dadurch lassen sich solche Fragen beantworten:
- Ist diese Abbuchung von der Kreditkarte normal? (Betrugserkennung)
- Ist das eine normale E-Mail? (Spam-Filter)
- Ist diese Dosis normal? (Fehlmedikation vermeiden)
Mit solchen Algorithmen können Unternehmen rechtzeitig reagieren, wenn Probleme entstehen. Sobald beispielsweise der Algorithmus einer Bank große Kapitalbewegungen auf Konten bemerkt, die eigentlich nicht dafür bekannt sind, schickt er automatisch eine Warnung und löst Prozesse aus, die diese Transaktionen überprüfen. So ein Alarm ließe sich auch auslösen, wenn die Kreditkarte in einem anderen Land verwendet wird als das Handy eines Nutzers. Das dürfte ein starker Hinweis auf Betrug sein.
Frage 3: Wie viel wird das?
Die dritte Frage, die Data Scientists beantworten können, ist: Wie viel wird es sein? Sie setzen in solchen Fällen auf maschinelles Lernen und prognostizieren Antworten durch Regressionsalgorithmen. Diese Algorithmen sagen den numerischen Wert einer Variable vorher, indem sie ihn von ihrem vorherigen Verhalten ableiten. Damit werden solche Fragen beantwortet:
- Wie groß wird der Umsatz im nächsten Quartal sein?
- Wie warm wird es morgen?
- Wie viel Terabyte an Daten werden die Mobilfunkkunden beim Oktoberfest übertragen?
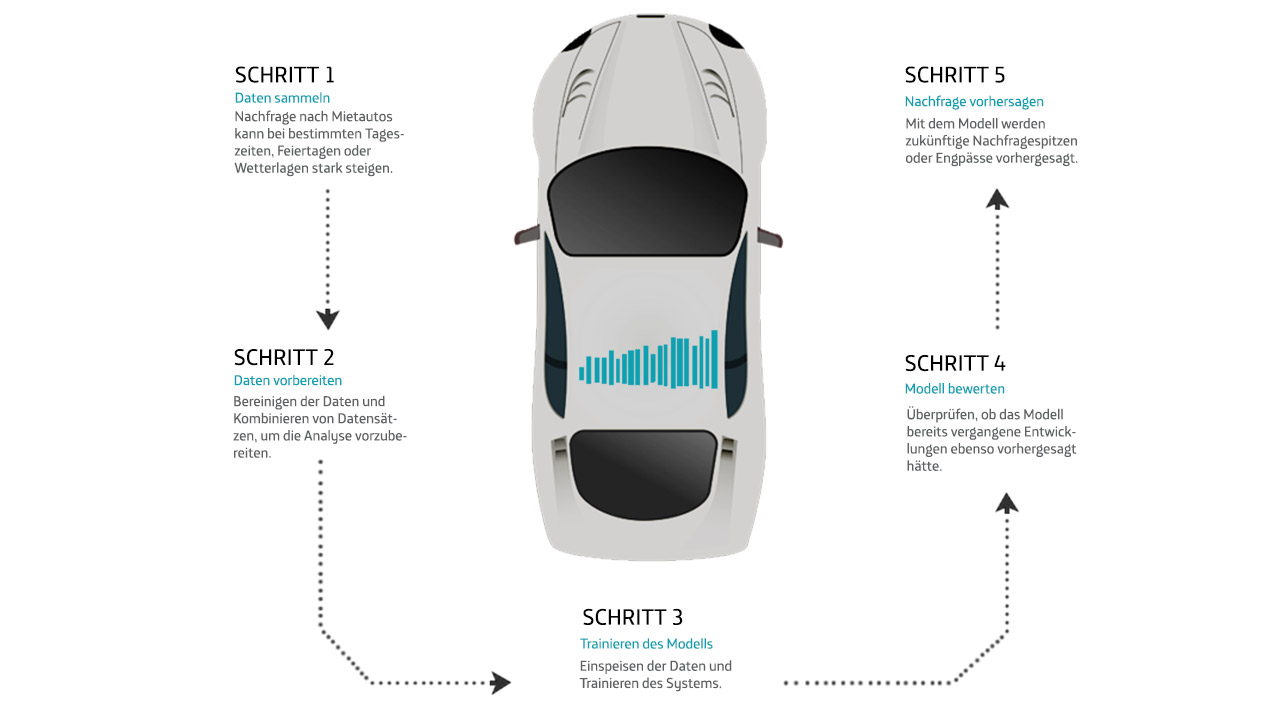
In diesem Bild sieht man, wie ein Autoverleih einen Regressionsalgorithmus einsetzen kann, um sein Angebot gemäß der erwarteten Nachfrage zu planen.
Frage 4: Wie ist das organisiert?
Die zwei letzten Fragen sind ein wenig komplizierter. Manchmal muss man die Struktur der Daten verstehen und erkennen, wie sie organisiert sind. Solche Strukturen sieht man gewöhnlich am besten, indem man die Daten in Gruppen einteilt, die jeweils aus ähnlichen Elementen bestehen. Diese Gruppen nennen sich Cluster. Man kann beispielsweise die Kunden von Video-on-Demand-Services nach ihren Lieblingsfilmen gruppieren.

Aber sie lassen sich auch nach sozio-ökonomischen Kriterien wie Alter, Geschlecht oder Bildungsniveau einteilen. Deshalb liefert die Anwendung solcher Clustering-Techniken nicht nur eine richtige Antwort, sondern gleich mehrere, die hilfreiche Informationen enthalten. Sie sind unter anderem nützlich, um Kundengruppen in unterschiedliche Segmente einzuteilen, ihre Vorlieben vorherzusagen oder auch um die richtigen Preise für Produkte festzulegen.
Damit können Unternehmen solche Fragen beantworten:
- Welche Druckermodelle haben denselben Fehler?
- Welche Bücher sollten wir diesem Kunden empfehlen?
- Welches personalisierte Angebot sollten wir an diesen Kunden richten?
Wenn wir verstehen, wie die Daten strukturiert sind, können wir damit zukünftiges Verhalten und Ereignisse verstehen und vorhersagen.
Frage 5: Und was sollen wir jetzt tun?
Um diese letzte Frage zu beantworten, werden Algorithmen angewendet, mit denen Maschinen durch Bestärkung lernen. Sie basieren auf Untersuchungen, die erforscht haben, wie man das Lernen bei Menschen und Ratten fördert, indem man Belohnungen und Bestrafungen einsetzt. Die Algorithmen verbessern sich, indem sie ihr Umfeld beobachten. Ihre Eingabeinformationen erhalten sie durch das Feedback, dass sie auf ihre eigenen Aktionen bekommen. Das System lernt also aus Fehlern nach der Trial-and-Error-Methode.

Die Algorithmen geben dabei Antworten auf Fragen, die beispielsweise Roboter oder Maschinen sich stellen könnten, wie:
- Ich bin ein autonomes Fahrzeug und das ist eine gelbe Ampel. Soll ich beschleunigen oder bremsen?
- Ich bin ein Roboter-Staubsauger und mein Akku ist nur noch zu 30 Prozent geladen. Soll ich weitersaugen oder zur Ladestation fahren und aufladen?
Die Superhelden aus der Data Science beantworten immer wieder dieselben fünf Grundfragen. Alle anderen Aufgabenstellungen sind nur Varianten davon. Und dennoch lassen sich damit ganze Berge von Daten nach nützlichen Informationen durchsuchen.
Empfehlung der Redaktion






Artikel teilen




Autor:in


